Was ist ein Datenbankmodell?
Es scheint zunächst naheliegend, dass bei einer Vielzahl von unterschiedlichen Anwendungsprogrammen jedes dieser Programme seine benötigten und verarbeiteten Daten in eigenen Formaten und in eigenen Dateien speichert. Dies begünstigt auch die Entwicklung von Anwendungen durch verschiedene Funktionsbereiche eines Unternehmens:
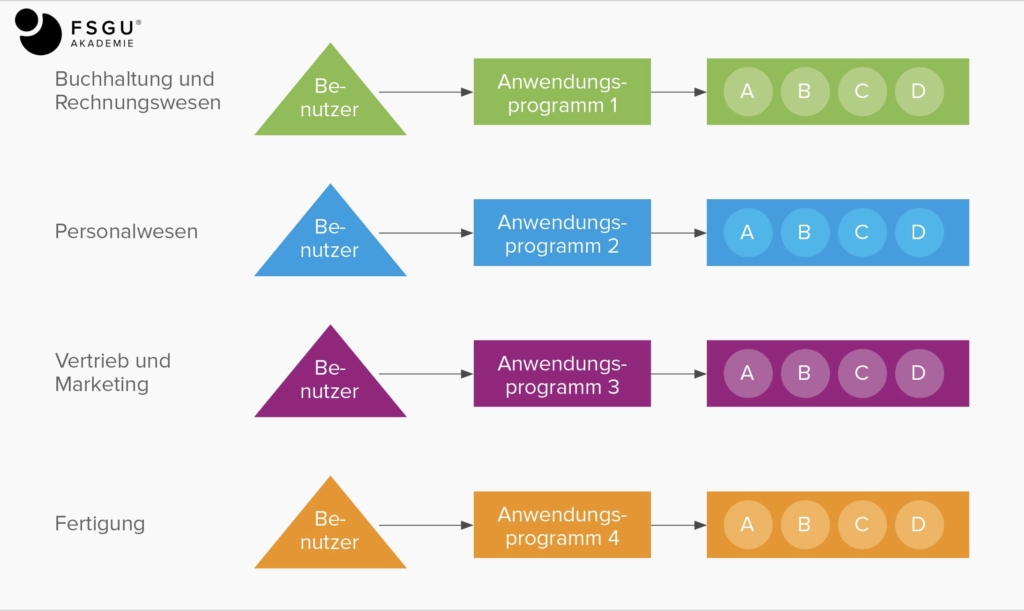
Grundsätzlich ist dies ein einfach nutzbarer Ansatz und in bestimmten Bereichen durchaus weit verbreitet. Es ergeben sich jedoch dadurch erhebliche Nachteile:
- Gleiche Daten müssen mehrfach eingegeben, verarbeitet und gespeichert werden. Es ergibt sich ein erhöhter Speicherplatzbedarf sowie vor allem die hohe Wahrscheinlichkeit von Inkonsistenzen (beispielsweise bei Namen oder Adressangaben)
- Daten müssen zwischen verschiedenen Systemen ausgetauscht werden, es ist eine Kommunikation bei Änderungen erforderlich
- Die Datenstrukturen sind eng an die Programmstrukturen gebunden – es resultiert eine geringe Datenunabhängigkeit und Daten müssen zwecks Austauschs zwischen Anwendungsprogrammen unter Umständen konvertiert werden etc.
- Der Implementierer ist für den Aufbau und den Inhalt der Daten und Dateien, für die Effizienz des Zugriffs, für die Integrität sowie für die Sicherheit der Daten verantwortlich
- Gleiche Aufgaben wie Speicherverwaltung, Rechteverwaltung oder Abfragen von Daten müssen in allen Anwendungsprogrammen gelöst werden
Als Lösungsansatz wurden Datenbanksysteme u.a. mit folgenden Aufgaben und Eigenschaften entwickelt:
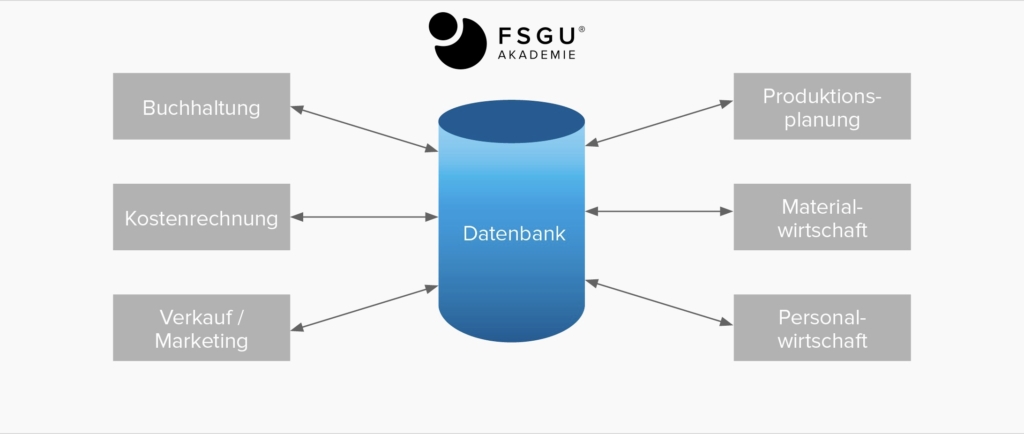
- Zentrale Kontrolle über die operationalen Daten – die Daten liegen nur an einem Ort vor, alle operationalen Daten können bzw. müssen gemeinsam benutzt werden, es gibt keine verstreuten privaten Daten und Querauswertungen auf Grund der inhaltlichen Zusammenhänge sind möglich
- Es wird ein hoher Grad an Datenunabhängigkeit (= Maß für die Isolation zwischen Anwendungsprogrammen und Daten) erzielt
- Hohe Leistung und Skalierbarkeit – Datenbanksysteme werden zur Speicherung und Manipulation von Daten optimiert und die Datenbanken können vergleichsweise einfach erweitert und angepasst werden
- Probleme der Datenspeicherung, der Dateiorganisation und der Datensicherung werden zentral gelöst
- Redundanz wird eliminiert, dadurch können Inkonsistenzen weitgehend vermieden werden und es gibt keine unterschiedlichen Änderungsstände
- Es gibt mächtige und einheitliche Sprachen zur Datenmanipulation und zur Abfrage von Daten
- Es gibt ein gemeinsames globales Modell eines Ausschnitts der realen Welt, welches für das Unternehmen relevant ist (= konzeptionelles Modell)
Was ist ein Datenbankmodell und aus welchen Konzepten setzt es sich zusammen?
Nach (Daum, 2006) und (Manthey, 2002): Ein Datenbankmodell ist ein System von Konzepten zur Beschreibung von Datenbanken. Das Datenbankmodell liefert zudem die Grundlage für Syntax und Semantik eines Datenbankschemas (und damit auch einer Datenbankprogrammiersprache).
Ein Datenmodell besteht aus einer bestimmten Zusammensetzung von Konzepten zur Modellierung von Daten in der realen Welt und/oder in einem Rechner (beispielsweise Tabellen im relationalen Modell oder Klassen im objektorientierten Modell).
Nach Edgar F. Codd definiert sich ein Datenbankmodell aus drei Eigenschaften:
- Einer Sammlung von Datenstrukturen
- Einer Menge von Operatoren, die auf jede der Datenstrukturen angewandt werden können, um Daten abzufragen oder abzuleiten
- Einer Menge von Integritätsregeln, die Veränderungen der Daten festlegen
Ein Datenbankschema ist ein formales Modell für die Struktur von Daten und beschreibt den Aufbau einer konkreten Datenbank auf Basis des Datenbankmodells, nämlich den Aufbau der Daten, die Basisdatentypen, zulässige Operationen auf Daten, mögliche Beziehungen sowie Konsistenz- und Integritätsbedingungen etc.
Das Datenbankschema ist in einer formalen Sprache – einer Datenbankprogrammiersprache (DBPL = Database Programming Language) – definiert; Beispiele hierfür sind
- In XML-Datenbanken -> Schema ist durch DTD (Document Type Definition) definiert
- In SQL-Datenbanken -> Schema ist durch DDL (Data Definition Language) definiert
Datenbanksysteme (Abk.: DBS) werden auf verschiedene Weise klassifiziert:
- generische DBS: sind für beliebige Anwendungen gedacht
- spezifische DBS: sind nur für spezielle Anwendungsfelder geeignet (z.B. Multimedia-Datenbank, Bild-Datenbank, Geo-Informationssystem)
Generische DBS werden meist nach dem unterstützten Datenmodell klassifiziert wie z.B.
- relationale Datenbanken
- objekt-orientierte Datenbanken
- hierarchische Datenbanken
- Entity-Relationship-Datenbanken
Was ist ein relationales Datenbankmodell?
Nach (Manthey, 2002) wird der Datenbank-Markt heute völlig von DB-Systemen dominiert, die das relationale Datenmodell unterstützen. Führende kommerzielle Hersteller von relationalen DB-Produkten sind u.a. Oracle, Microsoft mit Access und SQL Server, IBM mit DB2 und Informix, Sybase sowie Postgres und MySQL.
Die Bezeichnung „relational“ ist motiviert durch das mathematische Konzept der Relation. Das Relationenmodell wurde von E. F. Codd (1970) entwickelt. Man kann sich Relationen praktisch als Tabellen vorstellen, die aus einzelnen Datensätzen bestehen und die alle dieselbe (homogene) Feldstruktur aufweisen. Relationale Datenbanken sind im Wesentlichen Sammlungen von Relationen.

Nach (Henseler, 2018) sind relationale DBMS (RDBMS) derzeit marktbeherrschend, da die einfache Strukturierung in Tabellen recht benutzerfreundlich und für viele Anwendungsgebiete ideal ist. Weiterhin ist die strikte Trennung zwischen relationalem Datenmodell und Anwendungen mit wechselndem Programmierparadigma (Imperativ, Objektorientiert, Funktional, etc.) sehr erfolgreich.
Dennoch gibt es Anwendungsfälle, für die das relationale Modell nicht „passt“. Manchmal braucht man gewisse positive Eigenschaften des relationalen Modells gar nicht und gibt diese zu Gunsten anderer benötigter Eigenschaften auf.
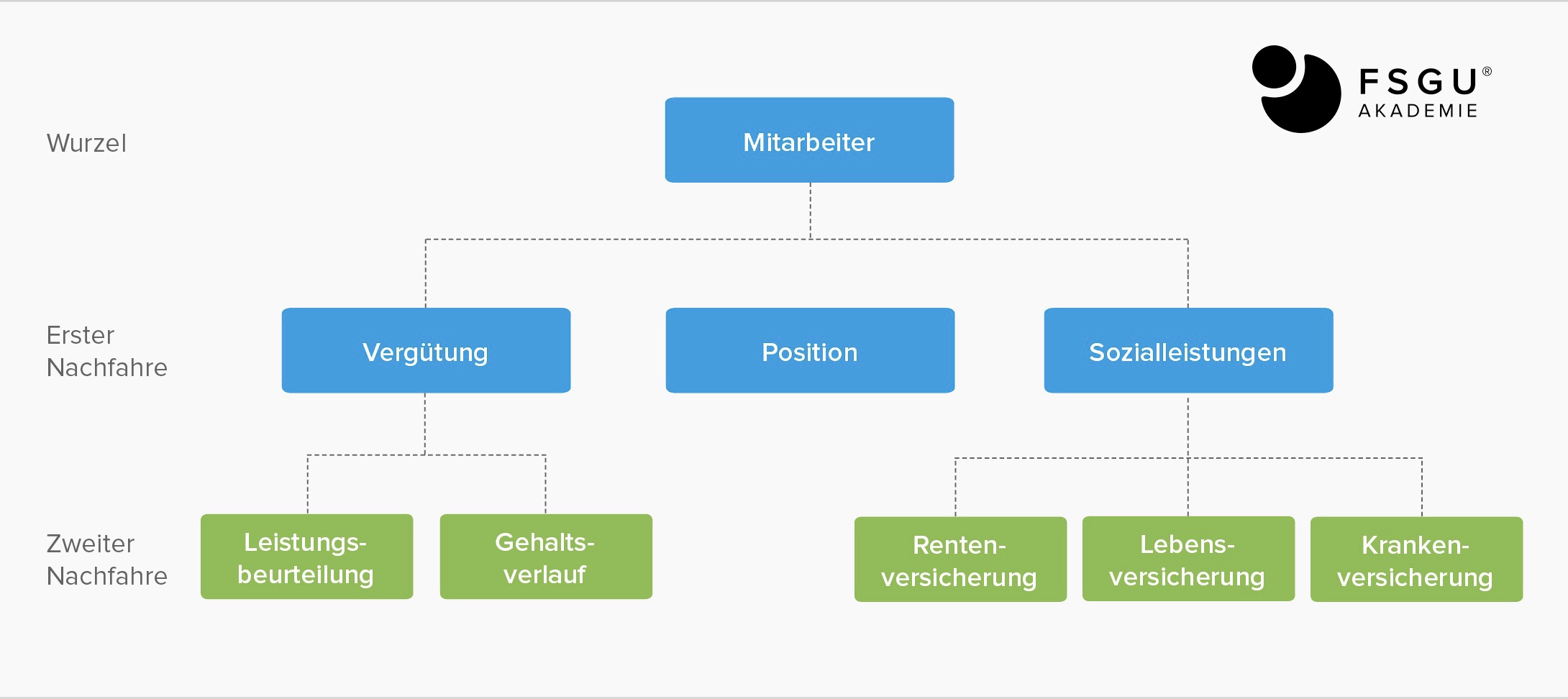
Was ist ein hierarchisches Modell?
Als frühester Ansatz der Datenspeicherung wurde dieses Modell seit den 1960ern implementiert. Dabei sind ausschließlich 1:m-Beziehungen (d.h. eins-zu-viele-Beziehungen) in einer Richtung erlaubt, so dass sich eine Baumstruktur ergibt. Beispiel: Eine Firma hat mehrere Kunden, welche mehrere Aufträge erteilen, die aus mehreren Positionen bestehen.
Ein Dateisystem hat auch heute noch ein hierarchisches Modell. Das unter Windows eingesetzte Active Directory oder die Registry folgt ebenfalls diesem Modell.
 Personalwesen“ class=“wp-image-213300″/>
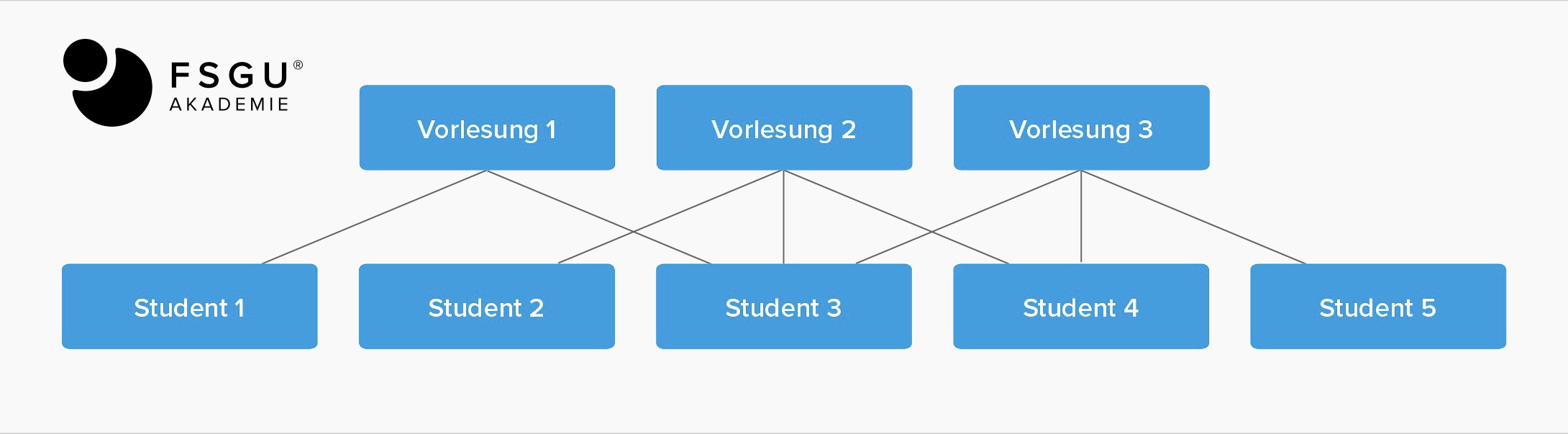
Personalwesen“ class=“wp-image-213300″/>Was ist ein Netzwerkmodell?
Als Erweiterung des hierarchischen Modells erlaubt das Netzwerkmodell seit ca. Anfang der 1970er Jahre die Modellierung von m:n-Beziehungen (also viele-zu-viele-Beziehungen, siehe auch 2.2 Entity-Relationship-Modell – Beziehungen). Anders als beim relationalen Modell werden die Beziehungen jedoch durch explizite Verweise (Referenzen) der Datensätze aufeinander modelliert und nicht durch matchen von Fremd- mit Primärschlüsseln.
Dieses Modell wurde unter der Bezeichnung CODASYL standardisiert. Die Anfragesprache ist nicht deskriptiv wie SQL (siehe 2.5 Datenbanksprachen), sondern navigierend. Änderungen im Schema sind deshalb nur durch umfangreiche Anpassungen der Clientanwendungen möglich.
Was sind objektorientierte Datenbanken?
Im relationalen Modell sind Informationen über ein „Objekt“ (wie einen Angestellten o.ä.) über mehrere Relationen „verstreut“ – d.h. die gefragte Information muss unter Umständen aus mehreren Relationen (via Verbundoperationen etc.) vergleichsweise umständlich zusammengesetzt werden.
In objektorientierten Datenbankmodellen hingegen wird die Gesamtheit der Informationen über einen Angestellten o.ä. in einem Datenobjekt „gehalten“ – eine entsprechende Anfrage betrifft dann auch nur dieses Objekt. Daraus resultiert u.a. eine Vereinfachung der Konsistenzregeln und ein Leistungsvorteil, weil z.B. bei einer Aktualisierung nicht die gesamte Datenbasis der DB nach eventuell betroffenen Tupeln (d.h. entsprechenden Datensätzen) abgesucht werden muss, wie dies im relationalen Modell der Fall wäre.
Diese Thematik versucht man auf zwei verschiedene Arten zu lösen:
- Erweiterung der RDBMS um komplexe Objekte in Objekt-Relationalen Datenbanken (ORDBMS)
- Entwicklung reiner objektorientierter Datenbanken (OODBMS)
Nach (Manthey, 2002): Seit Anfang der 1990er-Jahre gibt es Versuche einer Gruppe von Herstellern von objektorientierten Datenbanksystemen, ein OO-Datenmodell mit zugehöriger OO-DB-Sprache zu standardisieren. 1994 wurde von der Object Database Management Group (ODMG – http://www.odmg.org) ein erster Standard definiert. Dieser besteht aus einem Objektmodell, einer ODL (Object Definition Language) und einer OQL (Object Query Language) sowie Anbindungen an diverse objektorientierte Sprachen wie Java oder C++.
Die Anfragesprache OQL ist grundsätzlich ähnlich wie SQL (siehe 2.5 Datenbanksprachen) aufgebaut und beinhaltet zusätzlich komplexe Attribute, Referenzen und Methodenaufrufe. Einige Beispiele dazu aus (Bergner, 2020):
Name und Adressen der Gäste mit Reservierungen über mehr als 1 Tag:
select struct(x.RoomName,
(select struct(y.ArrivalDate, y.is_for_Guest.City
from y in x.is_reserved_in_Reservation))
from x in Room
Besteht eine Reservierung für die Kennedy Suite am 13 Mai?
exists x in Reservation : x.ArrivalDate= "13 May”
and x.is_for_Room.RoomName= “Kennedy”Ausgabe der Städte und Daten aller Gäste mit Reservierungen:
select struct(x.RoomName,
(select struct(y.ArrivalDate, y.is_for_Guest.City
from y in x.is_reserved_in_Reservation))
from x in RoomWas sind dokumentorientierte Datenbanken?
Was sind Informationssysteme?
Nicht alle Daten sind in Tabellenform strukturierbar. Denkt man z.B. an das Suchen in den Inhalten der Bücher einer Bücherei (nicht nur in Titel und Autor!) oder an die Suche von Webseiten, so liegen diese Daten als Dokumente vor. Diese Dokumente bestehen aus natürlich sprachlichem Text sowie Strukturinformationen (Inhaltsverzeichnis, Kapitel, Schriftauszeichnungen, etc.). Eine Anfrage kann nach Inhalten oder Metadaten erfolgen.
Beispiel:
Finde Lehrbücher zum Thema „Atomphysik“, in welchen auf die allgemeine Relativitätstheorie eingegangen wird und die nicht älter als 10 Jahre sind.
Das Informationssystem muss Synonyme für „Atomphysik“ kennen, aus dem Inhalt beurteilen, ob auf die allgemeine (und nicht die spezielle) Relativitätstheorie eingegangen wird und aus den Metadaten erkennen, wie alt das Buch ist. Gibt es mehrere Treffer, so müssen diese nach Relevanz sortiert werden, z.B. wie häufig kommt das Wort Atomphysik vor oder wie „nahe“ steht es im Buch an dem Begriff „Allgemeine Relativitätstheorie“.
Dies ist mit einem RDBMS ohne zusätzliche Erweiterungen nicht möglich, weshalb beispielsweise die Internet-Suchmaschine Google kein RDBMS benutzt.
Was sind XML-Datenbanken?
Mit dem XML-Hype kam Ende der 1990er schnell der Wunsch auf, XML-Dokumente in einer Datenbank abzulegen und zugreifbar zu machen. Zwar lassen sich XML-Dokumente durchaus auch in einem RDBMS ablegen (es gibt mehrere Möglichkeiten mit unterschiedlichen Vor-/Nachteilen), aber meist ist diese Abbildung nicht sehr performant.
Spezielle XML-Datenbanken sind ausschließlich auf das Speichern von und Suchen in großen XML-Dokumenten spezialisiert. Als Suchanfragesprache wird XQuery verwendet, welche große Ähnlichkeiten zu SQL aufweist.
Was sind NoSQL-Datenbanken?
Ausgehend von Anforderungen moderner Web 2.0-Techniken und dem Trend zum Cloud-Computing setzen diese Modelle seit einigen Jahren Eigenschaften in den Vordergrund, welche mit RDBMS nur mühsam zu erbringen sind. Man kann NoSQL auch als „Bewegung“ verstehen, nicht-relationale DBMS zu „erfinden“.
Überspitzt wird dies manchmal als „Postrelationales Modell“ bezeichnet, obwohl NoSQL-DBMS oft mit RDBMS zusammenarbeiten und sie keinesfalls ersetzen wollen.
Man verzichtet absichtlich auf einige positive Eigenschaften des relationalen Modells, gewinnt dabei aber neue Freiheiten. NoSQL steht ursprünglich für „Not Only-SQL“. Tatsächlich werden meist andere Anfragesprachen (z.B. JavaScript) verwendet anstelle von SQL.
Getrieben wurde dieses Datenbankmodell vor der Notwendigkeit der Skalierung sehr großer Datenmengen. Man unterscheidet dabei:
- vertikale Skalierung: Man steigert die Leistungsfähigkeit des Datenbankservers durch Einsatz von stärkerer Hardware (mehr und schnellere CPUs, Platten, Hauptspeicher, etc.) und/oder Spiegelserver im gleichen Rechenzentrum.
- horizontale Skalierung: Einsatz vieler, leistungsschwacher, dezentraler Rechner.
Durch die horizontale Skalierung entsteht ein verteiltes System mit dutzenden oder hunderten von Knoten, die durchaus über den ganzen Globus verteilt sein können.
Was sind temporale Datenbanken?
Temporale Datenbanken sind Datenbank-Systeme mit speziellen Operatoren für die Verwaltung zeitbehafteter Daten. Zunächst naheliegend scheint es, in z.B. relationalen Datenbanken eine Zeitstempelung durch „reguläre“ zeitwertige Attribute vorzunehmen:
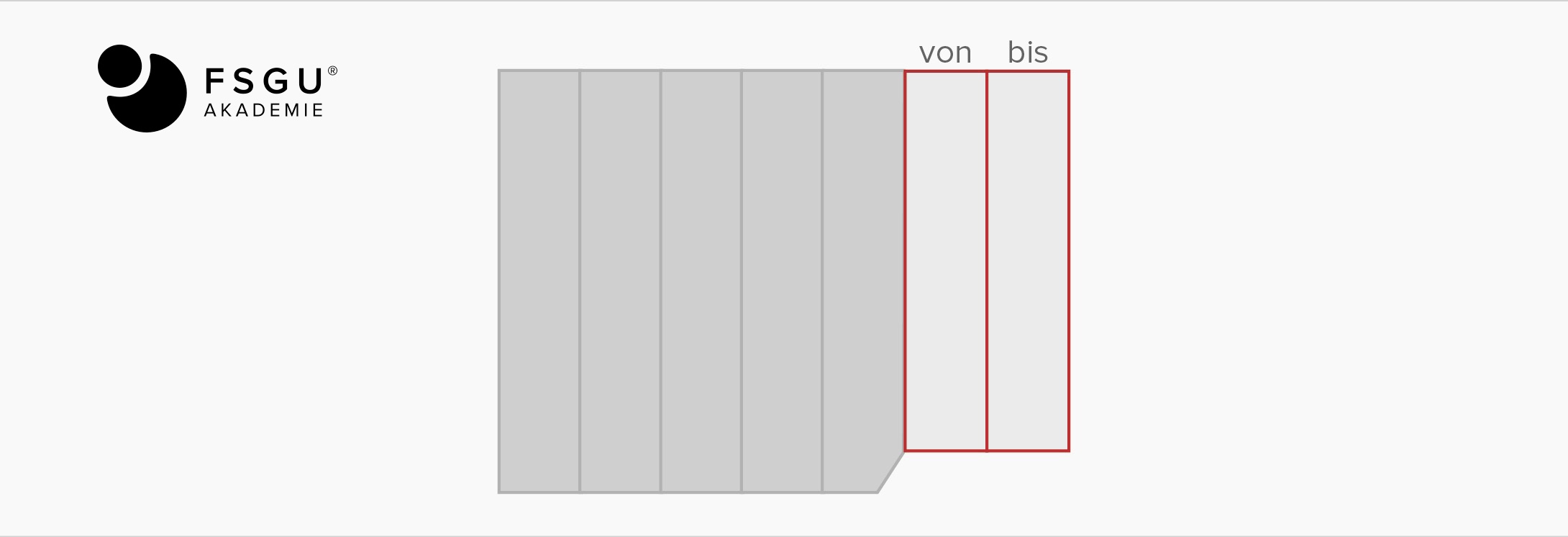
Allerdings werden dabei schon einfachste Anfragen mit Historienbezug dramatisch aufwändig in deren Formulierung. Die Modellierung zeitabhängiger Daten in einem DBMS stellt zusätzliche Anforderungen an den Zustand der Datenbank wie etwa
- Eindeutige Identifikation: wird eine bestehende Relation ohne Zeitstempel um einen solchen erweitert, sind die bisherigen Schlüsselkandidaten der Relation möglicherweise nicht mehr zur eindeutigen Identifizierung ausreichend: Mehrere verschiedene Tupel in der temporal erweiterten Relation würden nach dem nicht-temporalen Primärschlüssel als ein einziges Tupel identifiziert werden, wenn sich die Werte von nicht zum Primärschlüssel gehörenden Attributen im Laufe der Zeit verändern.
- Widerspruchsfreiheit: Für gewöhnlich wird davon ausgegangen, dass sich widersprechende Aussagen nicht zur gleichen Zeit gültig sind. Die Zeitstempel inhaltlich verschiedener Tupel einer Relation dürfen sich also nicht überlappen.
- Redundanzfreiheit: Redundanz tritt in temporalen Datenbanken auf, wenn sich die Zeitstempel inhaltlich gleicher Tupel überlappen: Die zu den Zeitpunkten in der Schnittmenge gehörenden Aussagen werden durch mehrere Tupel ausgedrückt. Außerdem sind verschiedene Aussagen redundant, wenn sie sich durch eine einzige ausdrücken lassen. Dies ist der Fall, wenn inhaltlich gleiche Tupel aneinander grenzende Zeitstempel haben.
Mit temporalen Datenmodellen wird eine bessere Unterstützung bei der Abbildung zeitlicher Phänomene angestrebt, als dies bei herkömmlichen Datenmodellen der Fall ist. Die Grundidee temporaler Datenmodelle ist die Unterstützung von Konzepten, welche eine systematische Behandlung und Dokumentation von Wertänderungen über die Zeit erlauben.
Was sind mehrdimensionale Datenbanken?
Aus (Meier, 2010): Bei operativen Datenbanken und Anwendungen konzentriert man sich auf einen klar definierten, funktionsorientierten Leistungsbereich. Transaktionen bezwecken, Daten für die Geschäftsabwicklung schnell und präzise bereitzustellen. Diese Art der Geschäftstätigkeit wird oft als Online Transaction Processing (Abk. OLTP) bezeichnet.
Da die operativen Datenbestände täglich neu überschrieben werden, gehen für den Anwender wichtige Entscheidungsgrundlagen verloren. Zudem sind diese Datenbanken primär für das laufende Geschäft und nicht für Analyse und Auswertung konzipiert worden. Aus diesen Gründen werden neben transaktionsorientierten Datenbeständen auch eigenständige Datenbanken und Anwendungen entwickelt, die der Datenanalyse und der Entscheidungsunterstützung dienen. Man spricht in diesem Zusammenhang von Online Analytical Processing oder OLAP.
Kernstück von OLAP ist eine multidimensionale Datenbank, in der alle entscheidungsrelevanten Sachverhalte nach beliebigen Auswertungsdimensionen abgelegt werden (multidimensionaler Datenwürfel oder Data Cube). Eine solche Datenbank kann recht umfangreich werden, da sie Entscheidungsgrößen zu unterschiedlichen Zeitpunkten enthält. Beispielsweise können in einer multidimensionalen Datenbank Absatzzahlen quartalsweise, nach Verkaufsregion und nach Produkten abgelegt und ausgewertet werden.
Das Beispiel in der Abbildung unten soll dies illustrieren. Hier interessieren drei Auswertungsdimensionen, nämlich Produkt, Region und Zeit. Der Begriff Dimension beschreibt die Achsen des mehrdimensionalen Würfels. Der Entwurf dieser Dimensionen ist bedeutend, werden doch entlang dieser Achsen Analysen und Auswertungen vorgenommen.
Die Reihenfolge der Dimensionen spielt keine Rolle, jeder Anwender kann und soll aus unterschiedlichen Blickwinkeln seine gewünschten Auswertungen vornehmen können. Beispielsweise priorisiert ein Produktmanager die Produktdimensionen oder ein Verkäufer möchte Verkaufszahlen nach seiner Region auflisten.
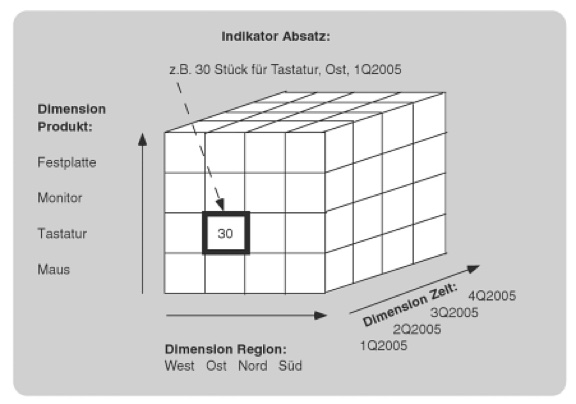
Die Dimensionen selber können weiter strukturiert sein. Die Dimension Produkt kann Produktgruppen enthalten, die Dimension Zeit könnte neben Quartalsangaben auch Tage, Wochen und Monate pro Jahr abdecken. Eine Dimension beschreibt somit die gewünschten Aggregationsstufen, die für die Auswertung des mehrdimensionalen Würfels gelten.
Was sind multimediale Datenbanken?
Nach (Severt, 2001): Ebenso wie für relationale Datenbanken ist auch für multimediale Datenbanken eine Akzeptanz einer Abfragesprache durch potenzielle Nutzer wichtig. Der SQL-Syntax ist dabei allgemein bekannt und akzeptiert. Früher gab es u.a. folgende Anfragesprachen:
- vollkommen neu und spezialisiert: PICQUERY+ 1993
- logische oder funktionelle Programmierung (EVA 1992)
- Erweiterungen von SQL (PSQL, VideoSQL, ESQL …)
Die Idee für MOQL (Multimedia Object Query Language) beruht auf der existierenden OQL (Object Query Language, siehe auch 1.1.2.4 Objektorientierte Datenbanken). Für Multimedia-Anfragen muss eine Abfragesprache universell sein, inhaltsbasierte Anfragen, räumliche und zeitliche Anfragen sowie unscharfe (fuzzy) Anfragen erlauben und Präsentationsfunktionen haben. MOQL hat dazu
- Erweiterungen in der where-Klausel von OQL-Anfragen um die Angabe
- räumlicher Beziehungen (spatial_expression)
- zeitlicher Beziehungen (temporal_expression)
- ‚beinhaltet‘-Beziehung (contains_predicate)
- Präsentationsfunktionen mittels present-Klausel
Beispielsweise gibt es für zeitliche Beziehungen bei Zeitintervallen die Funktionen equal, before, after, meet, metBy, overlap, overlappedBy, during, include, start, startedBy, finish sowie finishedBy, wobei Zeitintervalle eine obere und untere Grenze haben und Zeitpunkte gleich Zeitintervallen mit gleichen Grenzwerten sind.
Ein Beispiel aus einer Videoabfrage würde dann lauten ‚Finde den ersten Filmausschnitt mit Person MrX aus dem Video JamesB ‚
Select firstClip( select c from JamesB.clips c
where c contains MrX
order by lowerBound(c.timestamp) )