
Was ist die Aufgabe der Data Retrieval Language?
Inhaltsverzeichnis
Die Basis-Struktur von Abfragen lautet in einer einfachen Version
SELECT <attribut-liste> FROM <tabellen-liste> [ WHERE <bedingung> ]
Die attribut-liste bezeichnet all das, was von der Abfrage zurückgegeben werden soll. Die tabellen-liste beinhaltet alle Tabellen, die im Ergebnis und in der Bedingung involviert sind. Die bedingung ist ein boolescher Ausdruck und muss für jeden zurückgegebenen Wert True sein.
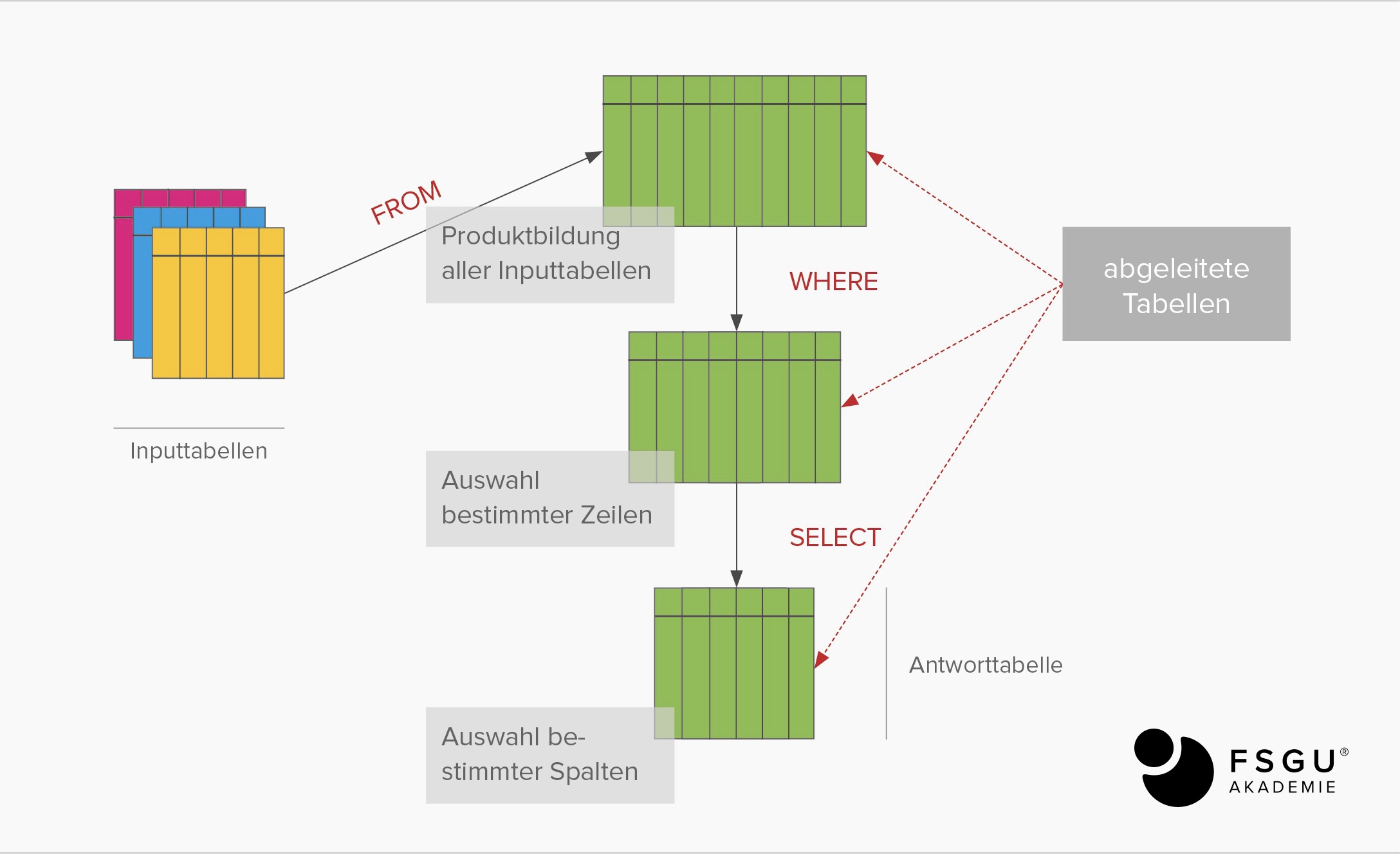
Die Komplexität von Abfragen ergibt sich durch die Möglichkeiten, Ausdrücke zu verwenden und durch eventuelle Unterabfragen (siehe Unterabfragen) sowie durch die teils komplexen Ausdrücke für Verbindungen zwischen Tabellen und die mögliche Komplexität der Bedingung.
Wie ist SELECT-Anweisung aufgebaut?
Die Struktur der SELECT-Anweisung lässt sich beispielsweise wie folgt darstellen:
| SELECT … | Projektion |
| FROM … | Relation / Produkt / Join |
| WHERE … | Selektion / Differenz / Durchschnitt |
| ALL / ANY / IN / EXISTS … | Division / Quantifizierung |
| GROUP BY … | Aggregation |
| UNION … | Vereinigung |
| ORDER BY … | Sortierung |
Verpflichtend dabei sind nur SELECT und FROM, alle anderen Operatoren sind optional. Für die Auswertungsreihenfolge gilt: FROM-Klausel vor WHERE-Klausel vor GROUP-Klausel vor HAVING-Klausel vor ORDER-Klausel vor SELECT-Klausel.
Zusätzlich gibt es eine Vielzahl von Schlüsselwörtern, welche die angeführten Elemente beispielsweise bei der Filterung von Datensätzen unterstützen. Diese werden im Folgenden auszugsweise näher betrachtet.
Beispiel einer Abfrage für den Gesamtumsatz nach Ländern:
SELECT N_NAME AS NAME, SUM(O_TOTALPRICE) AS TURNOVER
FROM ORDERS, CUSTOMER, NATION
WHERE O_CUSTKEY = C_CUSTKEY
AND C_NATIONKEY = N_NATIONKEY
GROUP BY N_NAME
HAVING SUM(O_TOTALPRICE) > 10000000
ORDER BY NAME
DISTINCT, AS
SELECT DISTINCT Name FROM Stadt
WHERE Einwohnerzahl > 10000
Mit dem optionalen Schlüsselwort DISTINCT lassen sich Duplikate ausblenden, die in einer Abfrage erscheinen können. Mit dem optionalen Schlüsselwort AS wird im Ergebnis ein Spaltenname (Attribut) umbenannt oder neu definiert.
Einige Beispiele hierzu:
SELECT Name FROM Stadt
Diese Abfrage liefert alle Städtenamen, die in der Tabelle Stadt gespeichert sind.
SELECT DISTINCT Name FROM Stadt
Diese Abfrage liefert nur die unterschiedlichen Städtenamen, die in der Tabelle Stadt gespeichert sind. Gäbe es beispielsweise mehrere Städte namens „St. Martin“, so würde die erste Abfrage alle Städte liefern, die zweite Abfrage nur alle – auch mehrfach enthaltenen Städtenamen – nur einmal.
Die SELECT-Anweisung kann mit einer WHERE-Klausel eingeschränkt werden. Sollen nur alle Städtenamen mit einer Einwohnerzahl größer als 10000 angezeigt werden, so lautet die Abfrage
SELECT DISTINCT Name FROM Stadt
WHERE Einwohnerzahl > 10000
Bisher wurde nur der Name der Städte zurückgegeben. Möchte man alle Informationen (beispielsweise
SELECT DISTINCT Name FROM Stadt
WHERE Einwohnerzahl > 10000
den Namen, das Bundesland, die Postleitzahl und ähnliches), die zu Städten gespeichert sind, wissen lautet die Abfrage
SELECT * FROM Stadt
Um in der Abfrage zusätzlich zum Namen und zur Postleitzahl eine neue Spalte mit dem Namen „Kategorie“ auszugeben, wird das Schlüsselwort AS verwendet. Die Abfrage bezeichnet alle Städte ab 5000 Einwohnern als Großstadt:
SELECT Stadt.Name AS NStadt, Land.Name AS NLand
FROM Stadt, Land
WHERE Stadt.Ländercode = Land.Ländercode
LIKE, BETWEEN, IN
Das LIKE-Prädikat unterstützt die Suche nach Datenstrings, von denen nur Teile bekannt sind (engl.: pattern matching). Dabei wird ein Datenwert mit einem Muster bzw. mit einer Maske verglichen. Die Maske wird mit Hilfe zweier spezieller Symbole gebildet:
‚%‘ bedeutet „null oder mehr beliebige Zeichen“
‚_‘ bedeutet „genau ein beliebiges Zeichen“
Das LIKE-Prädikat ergibt True, wenn der entsprechende Datenwert der aufgebauten Maske mit zulässigen Substitutionen von Zeichen für „%“ und “ _“ entspricht.
Beispiel:
Alle Städte, die mit „B“ beginnen, können wie folgt gefiltert werden:
SELECT * FROM Stadt
WHERE Name LIKE 'B%'
Mit dem BETWEEN-Prädikat lassen sich Werte auf einen Bereich einschränken. Der Ausdruck
y BETWEEN x AND z entspricht dabei (x ≤ y AND y ≤ z).
Beispiel:
SELECT NAME
FROM PERS
WHERE GEHALT BETWEEN 20000 AND 40000
Mit dem IN-Prädikat lassen sich Attribute auf Zugehörigkeit zu einer Menge testen. Der Ausdruck x IN (a, b, . . ., z) entspricht dabei (x = a OR x = b . . . OR x = z). Dies stellt eine explizite Mengendefinition dar; die Menge kann auch implizit durch eine verschachtelte Abfrage der Form x IN (SELECT …) vorgegeben werden.
JOIN
Wenn man mehrere Tabellen für eine Abfrage benötigt, kann eine Abfrage mit einem JOIN (Verbund) formuliert werden.
In der unten angegebenen Tabelle „Mitarbeiter“ soll die Spalte „Mitarbeiter-ID“ der Primärschlüssel sein (das heißt, dass zwei Sätze (Zeilen) nicht den gleichen Wert für die „Mitarbeiter-ID“ haben können – mit „Mitarbeiter-ID“ als Schlüssel könnten auch zwei unterschiedliche Personen mit gleichen Namen auseinander gehalten werden).
| Mitarbeiter-ID | Name |
| 01 | Müller |
| 02 | Mayer |
| 03 | Huber |
| 04 | Bauer |
Die folgende Order-Tabelle beinhaltet Bestellungen von Mitarbeitern, wobei gilt
- Die Spalte „Produkt-ID“ ist Primärschlüssel in „Orders“
- Die Spalte „Mitarbeiter-ID“ in „Orders“ verweist durch die Verwendung des Primärschlüssels aus „Mitarbeiter“ auf eine Person in „Mitarbeiter“
| Produkt-ID | Produkt | Mitarbeiter-ID |
| 234 | Drucker | 01 |
| 657 | Tisch | 03 |
| 865 | Sessel | 03 |
| 198 | Laptop |
Die Abfrage „Wer hat welches Produkt bestellt?“ könnte (in diesem einfachen Fall) wie folgt formuliert werden:
SELECT NAME
FROM PERS
WHERE GEHALT BETWEEN 20000 AND 40000
SELECT Mitarbeiter.Name, Orders.Produkt
FROM Mitarbeiter, Orders
WHERE Mitarbeiter.Mitarbeiter-ID = Orders.Mitarbeiter-ID
Das Ergebnis wäre in diesem Fall
| Name | Produkt |
| Müller | Drucker |
| Huber | Tisch |
| Huber | Sessel |
Die gleiche Abfrage kann mit JOIN wie folgt formuliert werden:
SELECT Mitarbeiter.Name, Orders.Produkt
FROM Mitarbeiter
INNER JOIN Orders
ON Mitarbeiter.Mitarbeiter_ID = Orders.Mitarbeiter-ID
INNER JOIN gibt Angaben zurück, die zueinander passen, d.h. in der Mitarbeiter-ID übereinstimmen. Falls Sätze aus Mitarbeiter keine Entsprechung in Orders haben, erscheinen sie nicht im Ergebnis.
LEFT JOIN gibt alle Sätze aus der linken Tabelle (Mitarbeiter) zurück, auch wenn es keinen Entsprechung in der rechten Tabelle (Orders) gibt. Falls es Sätze in Mitarbeiter gibt, die keine Order haben, werden sie auch ins Ergebnis aufgenommen, wobei fehlende Werte mit NULL-Werten aufgefüllt werden.Die Abfrage „Ermittle alle Mitarbeiter und ihre Bestellungen“, also
SELECT Mitarbeiter.Name, Orders.Produkt
FROM Mitarbeiter
LEFT JOIN Orders
ON Mitarbeiter.Mitarbeiter-ID = Orders.Mitarbeiter-ID
würde folgendes Ergebnis bringen:
| Name | Produkt |
| Müller | Drucker |
| Mayer | |
| Huber | Tisch |
| Huber | Sessel |
| Bauer |
In ähnlicher Weise gibt RIGHT JOIN alle Sätze aus der rechten Tabelle (Orders) zurück, auch wenn es keine Entsprechung in der linken Tabelle (Mitarbeiter) gibt. Falls es Sätze in Orders gibt, die keinen Mitarbeiter haben, werden sie auch ins Ergebnis aufgenommen, wobei fehlende Werte mit NULL-Werten aufgefüllt werden.
SELECT Mitarbeiter.Name, Orders.Produkt
FROM Mitarbeiter
RIGHT JOIN Orders
ON Mitarbeiter.Mitarbeiter-ID = Orders.Mitarbeiter-ID
würde folgendes Ergebnis bringen:
| Name | Produkt |
| Laptop | |
| Müller | Drucker |
| Huber | Tisch |
| Huber | Sessel |
Sortierung
Das ORDER BY Schlüsselwort benutzt man, um ein Resultat einer Abfrage zu sortieren. Die Sortierung kann aufsteigend (Schlüsselwort ASC für ascending) oder absteigend (Schlüsselwort DESC für descending) erfolgen, wobei aufsteigend als Standardsortierung gilt. Sortierungen können auch geschachtelt sein, d.h. zuerst wird nach dem ersten Kriterium sortiert, innerhalb gleicher Kriterienergebnisse nach dem zweiten Kriterium usw.
SELECT Firma, Bestellnummer FROM Orders ORDER BY Firma
Um die alphabetische Reihenfolge für die Spalte Firma und die numerische Reihenfolge für die Spalte Bestellnummer zu erzielen würde die Anweisung lauten
SELECT Firma, Bestellnummer FROM Orders ORDER BY Firma, Bestellnummer
Um die umgekehrte alphabetische Reihenfolge für die Spalte Firma und die normale numerische Reihenfolge für die Bestellnummer zu erzielen kann man schreiben
SELECT Firma, Bestellnummer FROM Orders ORDER BY Firma DESC, Bestellnummer ASC
Gruppierung
Mittels einer Gruppierung kann eine virtuelle Struktur über einer Tabelle definiert werden. Die Gruppierungsattribute fassen alle Zeilen der Tabelle jeweils zu einer Gruppe zusammen, die bezüglich aller Gruppierungsattribute gleiche Werte haben und zusätzlich die in einer optionalen HAVING-Klausel festgelegten Bedingungen erfüllen.
Beispiele:
Wie groß ist die durchschnittliche Einwohnerzahl der Städte der jeweiligen Länder?
SELECT Ländercode, AVG(Einwohner) FROM Stadt GROUP BY Ländercode
In welchen Ländern ist die durchschnittliche Einwohnerzahl kleiner 2 Millionen?
SELECT Ländercode, AVG(Einwohner) FROM Stadt GROUP BY LCode HAVING Einwohnerzahl < 2000000
Wie sind Unterabfragen aufgebaut?
Unterabfragen sind Abfragen innerhalb einer Abfrage oder einer Anweisung. Unterabfragen können an jeder Stelle, wo auch ein Ausdruck stehen kann, eingesetzt werden, somit auch in INSERT, DELETE und UPDATE-Statements. Anders formuliert: eine Anfrage heißt geschachtelt, wenn sie in der SELECT-, FROM-, oder WHERE-, bzw. HAVING-Klausel selbst wieder eine SQL-Anfrage enthält. Sie haben also sinngemäß die Form
WHERE <bedingung> [NOT] IN|<|>|... [ALL|SOME|ANY] (<Unterabfr.>)
Durch die Verschachtelung lassen sich z.B. Ergebnisse aus zwei oder mehreren Tabellen zusammensetzen, deren Inhalte spezifische Bedingungen erfüllen.
Beispiele von Unterabfragen:
SELECT N_NAME FROM NATION WHERE N_REGIONKEY IN (SELECT R_REGIONKEY FROM REGION WHERE R_NAME = ’EUROPE’)
SELECT * FROMhero h WHERE EXISTS (SELECT * FROMhasAliasa WHEREh.id=a.hero_id)
INSERT INTO heroesStartingWithA (SELECT * FROM heroes WHERE realName LIKE 'A%')
Was sind Aggregatfunktionen?
Manchmal betreffen die Informationen, die aus einer Tabelle abgerufen werden sollen, nicht einzelne Zeilen der Tabelle, sondern ganze Gruppe von Zeilen. SQL definiert zu diesem Zweck fünf Mengenfunktionen – auch Aggregatfunktionen – genannt. Jede dieser Funktionen führt eine Aktion aus, welche die Daten aus einer Menge von Zeilen und nicht aus einer einzelnen Zeile holt.
COUNT
Die Funktion COUNT gibt die Anzahl der Zeilen in der angegebenen Tabelle zurück.
Beispiel:
SELECT COUNT (*) FROM dozenten WHERE Land = 'Österreich'
MAX und MIN
Die Funktion MAX gibt den größten Wert in der angegebenen Spalte zurück, die Funktion MIN den kleinsten Wert.
Beispiel:
SELECT Vorname, Nachname, Lebensalter FROM Studenten WHERE Lebensalter = (SELECT MAX( Lebensalter ) FROM Studenten)
Mit dieser Abfrage (die eine Unterabfrage enthält) werden alle Studenten, die gleich alt sind wie der/die älteste StudentIn, zurückgegeben.
SUM
Die Funktion SUM addiert die Werte in der angegebenen Spalte. Der Datentyp muss dazu numerisch sein und der Wert der Summe muss innerhalb des Wertebereichs dieses Datentyps liegen.
Beispiel:
SELECT SUM( Umsatz ) FROM Rechnung
AVG
Die Funktion AVG gibt den Mittelwert aller Werte der angegebenen Spalte zurück. Wie bei der Funktion SUM muss der Datentyp der Spaltenwerte numerisch sein.
Beispiel:
SELECT AVG( Gewicht ) FROM Lieferungen
Beispiele
Wie viele Länder haben eine Mitgliedschaft in der EU?
SELECT COUNT(*) AS AnzahlLänder FROM Mitglied WHERE EU-Mitgliedschaft = True
Wie viele Länder gibt es in der Tabelle Land, wie groß ist die maximale, die minimale Fläche und die durchschnittliche Fläche aller Länder?
SELECT COUNT(Landname), MAX(Fläche), MIN(Fläche), AVG(Fläche) FROM Land