
Was bedeutet multidimensionale Datenmodellierung?
Inhaltsverzeichnis
„Klassische” Relationen sind (im nicht-mathematischen Sinn) eindimensional – eine Relation bildet Schlüssel auf Attributwerte ab. Oft sind jedoch mehrere Perspektiven („Dimensionen“) von Interesse, wie beispielsweise die Sicht des Geschäftserfolges nach Produkten, Zeit, Region, Filiale oder Manager etc. Solche Perspektiven sind nicht mit normalen Relationen darstellbar, weshalb man zu multidimensionalen Datenmodellen (und Datenbanksystemen) übergeht.
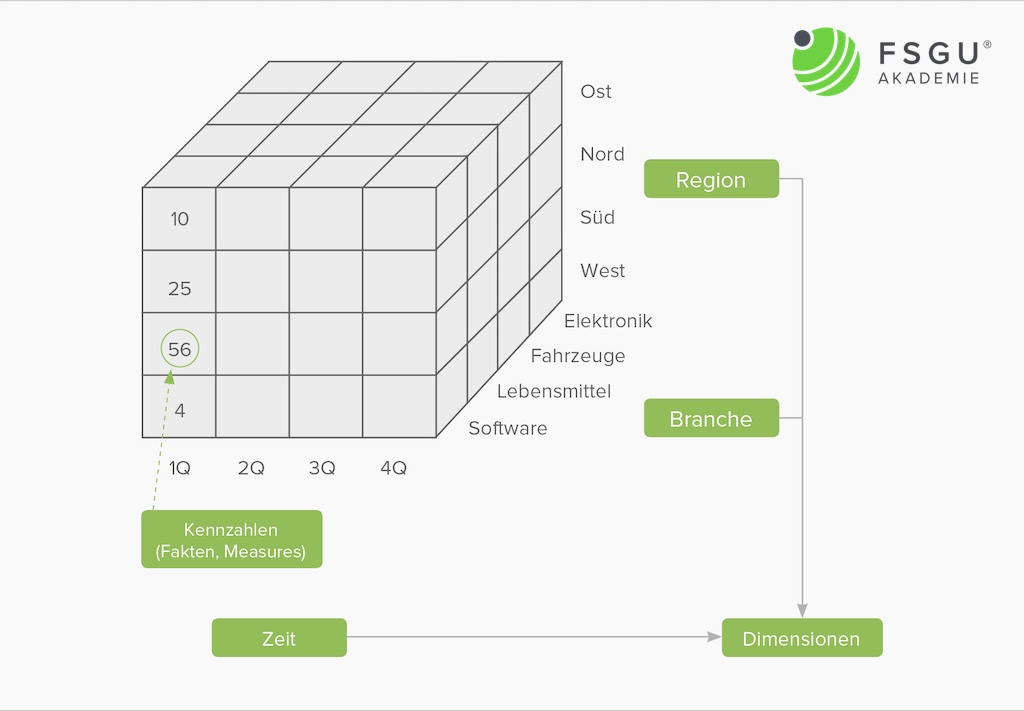
Die Grundidee der multidimensionalen Datenmodelle ist die Unterscheidung von Fakten (gemessene Werte), Dimensionen (Beschreibung der Messwerte in Raum, Zeit, Organisation, …) und Klassifikationshierarchien (Dimensionen haben eine hierarchische Struktur). Als Metapher dient ein Würfel (Cube) bzw. Hypercube. Fakten sind dabei Punkte im multidimensionalen Raum und Klassifikationshierarchien stellen Achsenbeschriftungen/Koordinaten in unterschiedlichem Verfeinerungsgrad dar (siehe dazu auch unten).
Analysen erfolgen durch Operationen auf dem Cube wie Dimensionen ausblenden/einblenden, Auswahl von Subwürfeln (Flächen, Punkten, …) oder Hierarchiestufe vergröbern/verfeinern.
Was sind die Kennzahlen bei der multidimensionale Datenmodellierung?
Kennzahlen (auch Fakten, Messgrößen, Measures, Measured Facts genannt) sind Größen mit konzentrierter Aussagekraft zur Diagnose, Überwachung und Steuerung eines Systems. Meist handelt es sich um betriebswirtschaftliche Größen, z.B. Umsatz, Gewinn oder Rentabilität. Es sind komplexe Beziehungen zwischen Kennzahlen möglich.
Kennzahlen besitzen beschreibende Attribute wie Einheit, Wertebereich oder Berechnungsvorschrift. Solche Vorschriften, die festlegen, wie eine Kennzahl berechnet wird (z.B. Gesamtpreis = Menge mal Einzelpreis) werden als Regel bezeichnet.
Was sind die Dimensionen bei der multidimensionale Datenmodellierung?
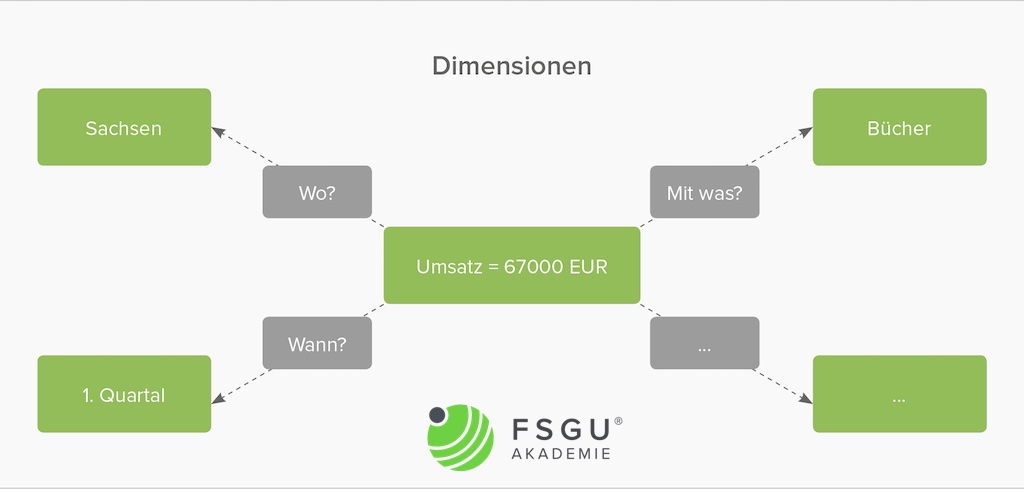
Die reinen Zahlenwerte einer Kennzahl sind ohne semantischen Bezug nichtssagend. Dimensionen setzen Kennzahlen in Bezug zu Eigenschaften bzw. sachlichen Kriterien und ermöglichen eine eindeutige Strukturierung des Datenraums.
Jede Dimension hat ein Schema wie beispielsweise
- Zeit mit Tag, Woche, Jahr etc.
- Region (Landkreis, Land, Staat, …)
- Produkt (Produktgruppe, Produktklasse, Produktfamilie, …)
und zugehörige Werte.
Dimensionen beschreiben somit Daten und ermöglichen den Zugriff auf Kennzahlen. Dimensionen spiegeln die unternehmerische Sichtweise wieder, nach der die Fakten aufgeschlüsselt werden (z.B. Kunden, Produkte, Regionen, Zeit) bzw. entsprechen der Auswertungsperspektive eines Anwendungsbereichs. Eine Dimension kann somit auch als Betrachtungsperspektive bezeichnet werden.
Innerhalb einer Dimension unterscheidet man zwischen Dimensionselementen, nach denen verdichtet wird (z.B. Produkt), und Dimensionsattributen, die lediglich beschreibenden Charakter haben (z.B. Abmessungen).
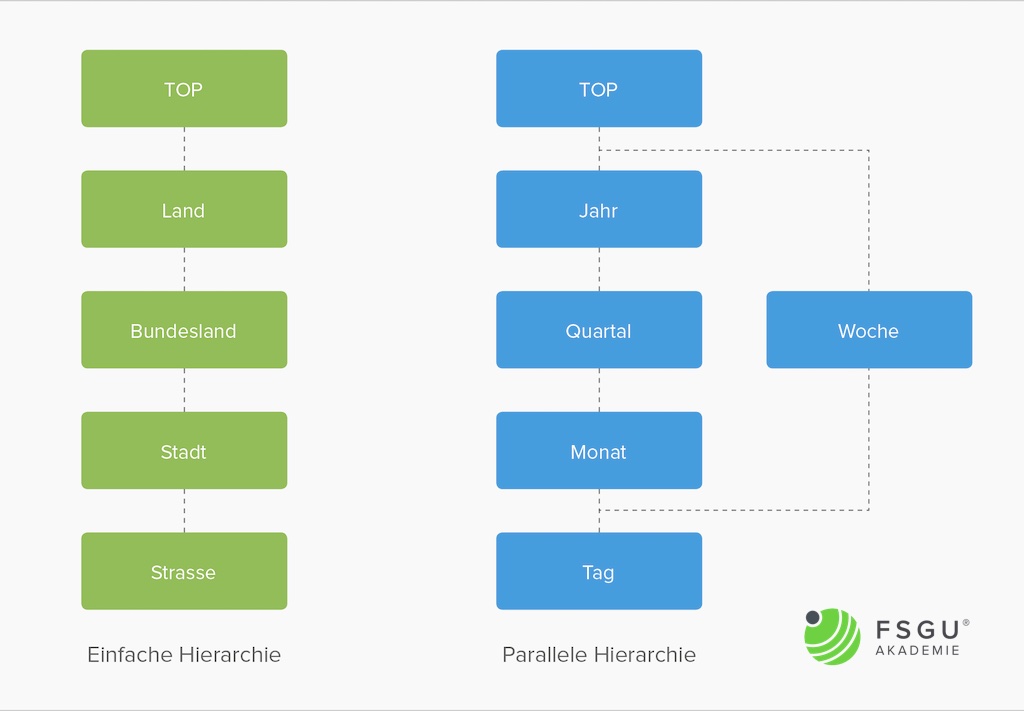
Die Dimensionen lassen sich in diesem Sinne zu Hierarchien verdichten (z.B. Kunde – Kundengruppe oder Monat – Quartal – Jahr). Bei einfachen Hierarchien enthalten die jeweils höheren Hierarchieebenen die aggregierten Werte der jeweils niedrigeren Ebene. Der oberste Knoten ist der Gesamtknoten. Parallele Hierarchien entstehen bei unterschiedlicher Art der Gruppierung, die Äste verlaufen parallel und ohne Beziehung – es wird jeweils ein Teilaspekt der Hierarchie pro Ast betrachtet.
Was ist ein Datenwürfel?
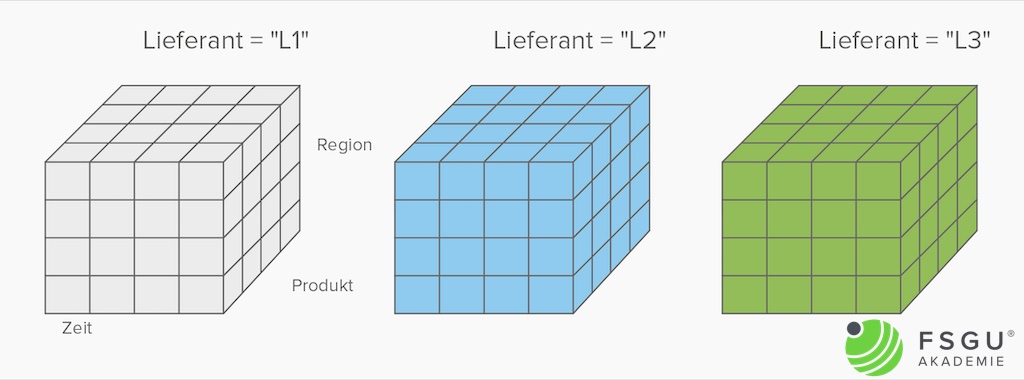
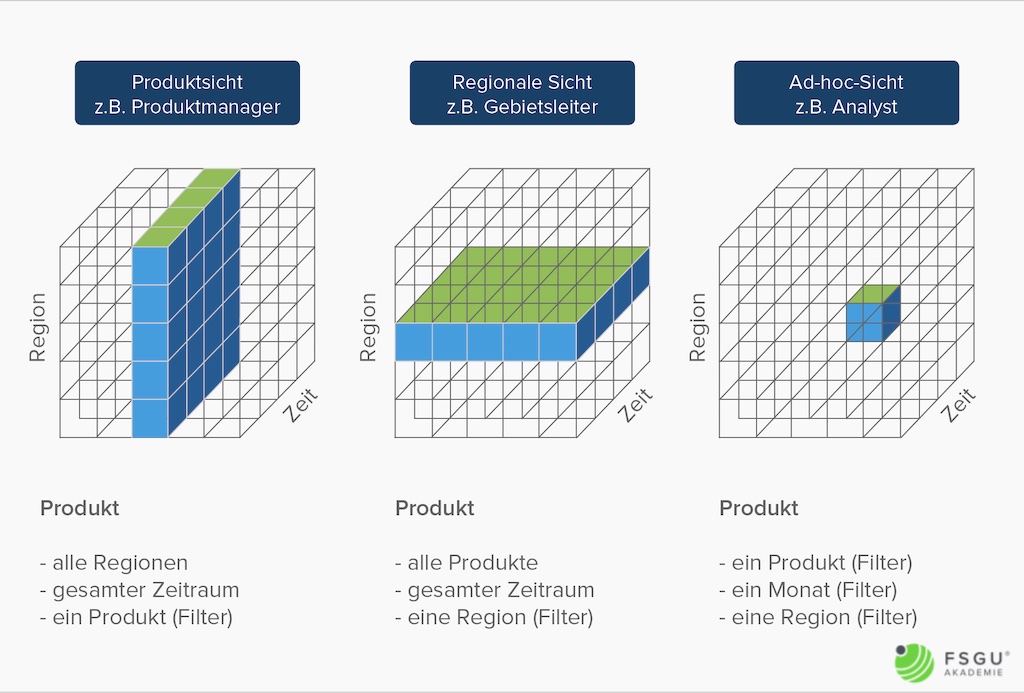
Ein Datenwürfel – auch Data Cube, Cube, Hypercube oder OLAP-Würfel genannt – ist ein multidimensional organisierter Raum von Fakten. Die Dimensionen entsprechen den Koordinaten, die Kennzahlen entsprechen den Zellen im Schnittpunkt der Koordinaten. Ein Cube hat typisch 4 bis 12 Dimensionen, wobei die Zeitdimension fast immer dabei ist. Weitere Standarddimensionen sind Produkte, Kunden, Verkäufer, Region, Lieferanten etc. Die Anzahl der Dimensionen wird als Dimensionalität bezeichnet.
Der dreidimensionale Würfel dient nur als Veranschaulichung für n-dimensionale Strukturen.
Ein 4D-Cube kann als Menge von 3D-Cubes dargestellt werden.
Was bedeutet Datenanalyse und welche Analysewerkzeuge kommen zum Einsatz?
Damit die im Data Warehouse abgelegten Daten zur Informationsgewinnung eingesetzt werden können, sind Anwendungen erforderlich, mit denen die gewünschten Analysen durchgeführt werden können. Dabei werden im Rahmen der Datenanalyse Einzeldaten wie z.B. Zeitbereiche verdichtet und Zusammenhänge, Abhängigkeiten sowie Strukturen untersucht.
Die Datenanalyse kann auf Basis unterschiedlicher statistischer Methoden erfolgen. Die auf Data Warehouse-Lösungen basierenden Ansätze sind On-Line Analytical Processing (Abk. OLAP) sowie Data Mining.
OLAP ist ein Ansatz zur Analyse von Daten, die in einem multidimensionalen Datenmodell vorliegen. Im OLAP kann die Datenanalyse auf verschiedenen Hierarchiestufen und aus unterschiedlichen Perspektiven durchgeführt werden. Typisch für OLAP ist, dass der Anwender Zusammenhänge oder die Ergebnisart kennen muss, um die relevanten Fragestellungen zu formulieren. Datenmuster und Beziehungen, für die keine hinreichend formulierten Anfragen existieren, können nicht aufgedeckt werden.
Unter dem Begriff Data Mining sind verschiedene Methoden der Datenanalyse anzusiedeln. Die Zielsetzung besteht jeweils darin, nützliche bzw. interessante Muster bzw. Zusammenhänge in den vorhandenen Daten aufzudecken und abzubilden. Je nach Aufgabenstellung sind unterschiedliche Data Mining-Methoden möglich (z.B. Visualisierungsverfahren, Clusterverfahren oder Entscheidungs-baumverfahren).